Extract, transform, load — and the many ways it goes wrong
4.1 The puzzle
A pipeline ran for eighteen months without complaint. It ingested GeoJSON feature collections from a municipal permits API every night, ran a handful of spatial joins against a PostGIS database, and wrote summary rows into a reporting table. Nothing exotic. Monitoring showed green. The pipeline completed in under four minutes each run.
Then someone noticed the permit count by district had been wrong for about six weeks. Not dramatically wrong — close enough that no alert fired. Wrong by around four percent, consistently biased toward under-reporting in three specific districts.
The cause, traced back: the upstream API had added a new field called district_code and quietly changed the type of the old field district_id from integer to string. The pipeline’s extraction step used district_id as a join key against a PostGIS dimension table that expected an integer. PostgreSQL cast the string silently in some cases, failed silently in others (NULLed the join), and the aggregation downstream summed fewer records without raising an error. The pipeline had been reporting counts as if the data were complete.
This is the canonical silent corruption failure. The system ran. It produced output. The output was wrong. No exception was raised anywhere in the execution graph.
The interesting thing is that this failure is entirely predictable from the pipeline’s structure, not from the specific nature of the bug. The same structure — extract, cast implicitly, join on assumed type, aggregate without null checking — will produce silent corruption whenever assumptions about the source data change. The specific type mismatch was an accident. The absence of validation that would have caught it was a design decision.
4.2 Three failure modes of ETL
Every ETL pipeline that runs in production long enough will encounter one of three failure modes. They are worth naming precisely because they have different causes, different signatures, and different fixes.
4.2.1 Silent data corruption
Schema drift: the upstream data source changes its structure without notice. Field names, data types, enumeration values, null handling, encoding — any of these can change. Your pipeline was written for the old structure. If your code is defensive, it raises an exception and you get paged. If it is not, it produces wrong output quietly.
The feedback structure here is what Systems Thinking Ch 6 calls feedback starvation. A balancing loop exists in principle — the loop from data quality degradation, to detection, to pipeline correction — but the loop is severed at the detection point. Monitoring checks pipeline completion, not output correctness. The corrective signal never reaches the engineer. The stock of data errors accumulates.
This failure mode is not prevented by better code. It is prevented by schema validation at the extraction boundary: assert what you expect to be true about the source data before any transformation runs.
4.2.2 Backlog growth
The second failure mode is structural, not logical. Your pipeline is designed to process N records per run. Your upstream source begins generating N+k records per run. The pipeline completes successfully every time. But each run leaves k records unprocessed, or processes them but delays their appearance by one cycle.
This is a stock accumulation problem. The backlog is a stock. The inflow is the arrival rate. The outflow is the processing rate. When inflow exceeds outflow, the stock grows. Continuously.
The signature of backlog growth is subtle: pipeline latency increases gradually. Reports lag by one day, then two. Downstream consumers start seeing “stale” data but cannot point to a failure. Eventually something downstream depends on a record that was supposed to arrive three days ago.
The fix is not to speed up the pipeline. The fix is to measure the backlog and set an alert before it reaches a problematic level — and then understand whether the design needs to change throughput, sharding, or scheduling.
4.2.3 Brittle dependencies
The third failure mode: an upstream API or data source changes its interface. Authentication scheme, endpoint URL, response format, rate limiting behaviour. Your pipeline breaks, sometimes hard (exceptions, immediate failure) and sometimes soft (wrong data, see failure mode one).
The feedback structure is a reinforcing fragility loop: the more your pipeline is tuned to the exact current behaviour of the upstream source, the larger the surface area for breakage, and the more effort any change requires. Teams that solve this by hardcoding API behaviour accumulate technical debt that grows with every upstream change.
The fix is interface abstraction: write a thin extraction layer whose job is to normalise the upstream source into a stable internal schema. All downstream transformation code works against the internal schema, not the upstream API. When the upstream changes, you update the extraction layer, not the transformation layer.
4.3 dbt: the transformation layer
dbt (data build tool) is not an ingestion tool. It does not move data from sources into your warehouse. It transforms data that is already in your warehouse. This distinction matters because dbt is the tool you use to make transformation auditable, testable, and reproducible — and you can only do that on data you already have.
A dbt model is a SQL SELECT statement in a .sql file. dbt compiles it into a CREATE TABLE AS or CREATE VIEW AS statement and runs it. The model’s name becomes the table name. If you reference another model with { ref('other_model') }, dbt builds the dependency graph and runs models in the right order.
-- models/permits/permits_by_district.sql-- Aggregates validated permit records to district level.-- Depends on: stg_permits (staging), dim_districts (dimension)with validated_permits as (select permit_id,cast(district_id asinteger) as district_id, issued_date::dateas issued_date, permit_type, geometryfrom {{ ref('stg_permits') }}where district_id isnotnulland district_id ~ '^\d+$'-- only cast rows that are numeric strings),joined as (select p.permit_id, p.permit_type, p.issued_date, d.district_name, d.district_code, ST_Within(p.geometry, d.boundary) as within_boundaryfrom validated_permits pinnerjoin {{ ref('dim_districts') }} doncast(p.district_id asinteger) = d.district_id)select district_code, district_name, permit_type, date_trunc('month', issued_date) asmonth,count(*) as permit_count,count(*) filter (where within_boundary) as within_boundary_countfrom joinedgroupby1, 2, 3, 4
The companion schema file declares tests. These run every time the model runs.
# models/permits/schema.ymlversion:2models:-name: permits_by_district description: > Monthly permit counts by district. One row per district × permit_type × month. Null district_ids are excluded at the staging layer.columns:-name: district_codedescription: Canonical district identifier from dim_districts.tests:- not_null-relationships:to: ref('dim_districts')field: district_code-name: permit_countdescription: Total permits issued in this district, type, and month.tests:- not_null-dbt_utils.accepted_range:min_value:0-name: monthtests:- not_nulltests:-dbt_utils.unique_combination_of_columns:combination_of_columns:- district_code- permit_type- month
The relationships test is the fix to the silent corruption failure described above. If district_code in permits_by_district references a value not present in dim_districts, the test fails loudly. The pipeline stops. You get paged. The wrong data never reaches the reporting table.
dbt tests are not nice-to-have. They are the only mechanism that detects silent schema drift before it propagates downstream. A dbt model without tests is a transformation that can silently corrupt its output when upstream data changes.
The lineage graph is a side effect of how dbt resolves { ref() } calls. Every model’s dependencies are known before the pipeline runs. You can trace the path from any column in any output table back to its source. When a bug is found in a downstream table, the lineage graph tells you exactly which models to inspect. This is not documentation you have to write — it is a structural property of the code.
4.4 Prefect: orchestration
dbt handles transformation. Prefect handles the surrounding machinery: scheduling, dependency ordering, retries, parameterisation, and observability.
A Prefect flow is a Python function decorated with @flow. A task is a Python function decorated with @task. Tasks can be retried on failure, cached on their inputs, and run concurrently where there are no dependencies between them. The Prefect server tracks every run, its state, and its logs.
The following flow ingests a GeoJSON file, validates that every feature has a non-null geometry and a required district_id property, and writes the valid records to PostGIS. Invalid records are written to a rejection table with an error reason, rather than being silently dropped.
# flows/ingest_permits.py"""Nightly permit ingestion: GeoJSON → PostGIS.Requires: PREFECT_API_URL, DATABASE_URL environment variables."""from __future__ import annotationsimport jsonimport loggingfrom pathlib import Pathfrom typing import Anyimport httpximport psycopg2from psycopg2.extras import execute_valuesfrom prefect import flow, task, get_run_loggerfrom prefect.tasks import task_input_hashfrom datetime import timedeltaPERMITS_API ="https://data.example-city.gov/api/permits/v2/geojson"REQUIRED_PROPERTIES = {"district_id", "permit_type", "issued_date"}@task( retries=3, retry_delay_seconds=60, cache_key_fn=task_input_hash, cache_expiration=timedelta(hours=1),)def extract_geojson(url: str) ->dict:"""Fetch a GeoJSON FeatureCollection from a URL. Retries three times on network failure. The cache key is the URL, so a re-run within the cache window does not re-fetch the source. This is the idempotency boundary for the extraction step. """ logger = get_run_logger() logger.info("Fetching %s", url) response = httpx.get(url, timeout=30) response.raise_for_status() data = response.json()if data.get("type") !="FeatureCollection":raiseValueError(f"Expected FeatureCollection, got {data.get('type')!r}") logger.info("Fetched %d features", len(data.get("features", [])))return data@taskdef validate_features( geojson: dict,) ->tuple[list[dict], list[dict]]:"""Validate geometry presence and required properties. Returns (valid_features, rejected_features). Rejected features include an 'rejection_reason' key — they are written to a separate table, not silently dropped. """ valid, rejected = [], []for i, feature inenumerate(geojson.get("features", [])): reasons = []# Geometry check geom = feature.get("geometry")if geom isNone: reasons.append("null_geometry")elif geom.get("type") notin {"Point", "LineString", "Polygon","MultiPoint", "MultiLineString", "MultiPolygon", }: reasons.append(f"unsupported_geometry_type:{geom.get('type')}")# Required properties props = feature.get("properties") or {} missing = REQUIRED_PROPERTIES - props.keys()if missing: reasons.append(f"missing_properties:{','.join(sorted(missing))}")# district_id must be castable to integer district_id = props.get("district_id")if district_id isnotNone:try:int(district_id)except (ValueError, TypeError): reasons.append(f"non_integer_district_id:{district_id!r}")if reasons: feature =dict(feature) feature["rejection_reason"] ="; ".join(reasons) rejected.append(feature)else: valid.append(feature)return valid, rejected@taskdef load_to_postgis( valid_features: list[dict], rejected_features: list[dict], conn_string: str,) ->dict[str, int]:"""Write valid features to permits_staging, rejects to permits_rejected. Uses INSERT ... ON CONFLICT DO UPDATE (upsert) on permit_id so the task is idempotent — re-running it for the same dataset does not produce duplicate rows. """ifnot valid_features andnot rejected_features:return {"inserted": 0, "rejected": 0} conn = psycopg2.connect(conn_string)try:with conn.cursor() as cur:if valid_features: rows = [ ( f["properties"]["permit_id"],str(f["properties"]["district_id"]), f["properties"]["permit_type"], f["properties"]["issued_date"], json.dumps(f["geometry"]), )for f in valid_features ] execute_values( cur,""" INSERT INTO permits_staging (permit_id, district_id, permit_type, issued_date, geom_json) VALUES %s ON CONFLICT (permit_id) DO UPDATE SET district_id = EXCLUDED.district_id, permit_type = EXCLUDED.permit_type, issued_date = EXCLUDED.issued_date, geom_json = EXCLUDED.geom_json, updated_at = now() """, rows, )if rejected_features: reject_rows = [ ( json.dumps(f), f.get("rejection_reason", "unknown"), )for f in rejected_features ] execute_values( cur,""" INSERT INTO permits_rejected (raw_feature, rejection_reason) VALUES %s """, reject_rows, ) conn.commit()finally: conn.close()return {"inserted": len(valid_features), "rejected": len(rejected_features)}@flow(name="ingest-permits-nightly")def ingest_permits( url: str= PERMITS_API, conn_string: str="",) ->None:"""Nightly permit ingestion flow. The flow is designed to be re-runnable: extraction is cached for one hour (re-runs within the window skip the API call), and the load step upserts on permit_id (re-runs do not create duplicates). """ logger = get_run_logger() geojson = extract_geojson(url) valid, rejected = validate_features(geojson) logger.info("Validation complete: %d valid, %d rejected",len(valid), len(rejected), )if rejected: logger.warning("%d features rejected. Inspect permits_rejected table.",len(rejected), ) result = load_to_postgis(valid, rejected, conn_string) logger.info("Load complete: %s", result)
Several design decisions in this code are worth making explicit.
The extraction task is cached on its input URL for one hour. If the flow is re-run within that window — because of a downstream failure, a manual retry, or a deployment event — the extraction step does not re-hit the API. This matters because many municipal data APIs have rate limits, and because idempotent re-runs should not cause N calls to the upstream for one logical ingest.
The validation task does not raise an exception on bad records. It returns two lists. The loading task writes bad records to a rejection table with a reason. This is the correct behaviour: a validation failure on 2% of records should not abort the ingest of the other 98%, but the 2% should not disappear either. They should be visible, auditable, and recoverable.
The load task uses upsert on permit_id. This is the key idempotency mechanism for the load step, discussed in detail below.
4.5 The backlog stock
Consider the following system. Your pipeline has a fixed processing capacity: it can process C records per run. Your upstream source arrives at rate R records per run. When R ≤ C, the pipeline processes all incoming data each run. When R > C, there is a surplus each run.
That surplus is a stock. It accumulates. Each run adds R records and removes C records. The net change per run is R − C. After n runs, the backlog is n(R − C).
This is not a degenerate edge case. Traffic data sources frequently have variable arrival rates that spike during incidents. Satellite imagery ingest from an active acquisition campaign can temporarily exceed a pipeline’s tiling capacity. Municipal permit data can surge after a planning deadline.
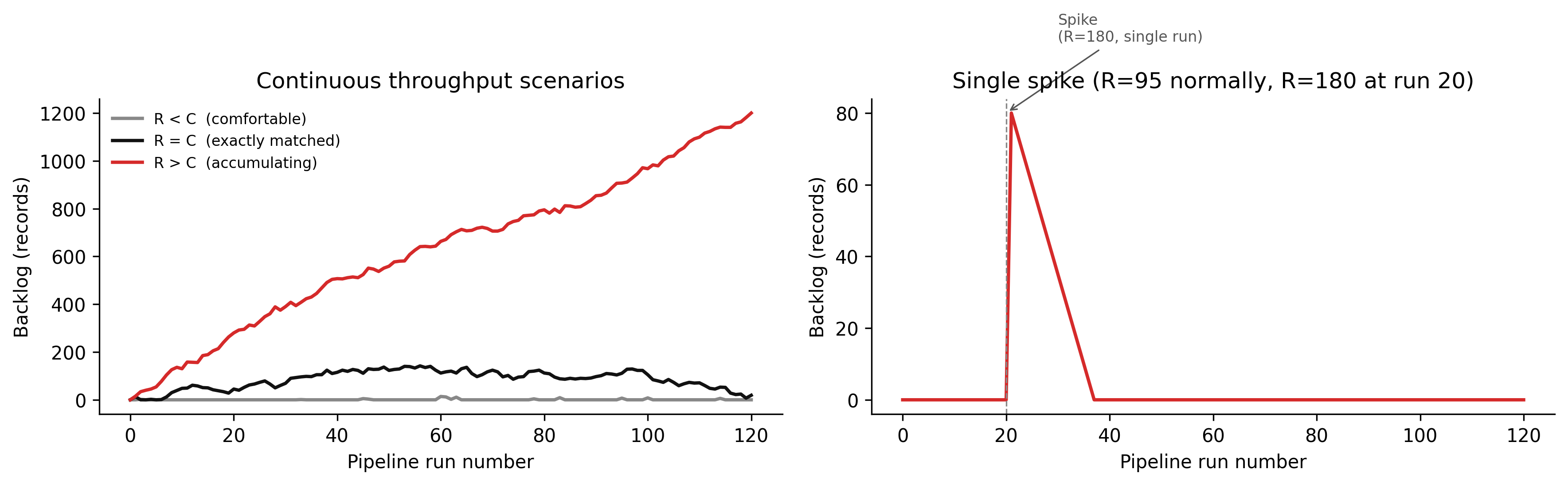
The following simulation shows three throughput scenarios — R < C (comfortable headroom), R = C (exactly matched), and R > C (accumulating backlog) — and shows the backlog stock over time under each.
Code
import numpy as npimport matplotlib.pyplot as pltrng = np.random.default_rng(42)n_runs =120scenarios = [# (label, base_ingest_rate, capacity, colour) ("R < C (comfortable)", 90, 100, "#888888"), ("R = C (exactly matched)", 100, 100, "#111111"), ("R > C (accumulating)", 110, 100, "#d52a2a"),]fig, axes = plt.subplots(1, 2, figsize=(12, 4), dpi=150)ax_left, ax_right = axesfor label, R_base, C, colour in scenarios: backlog = np.zeros(n_runs +1) arrivals = np.zeros(n_runs)for t inrange(n_runs):# Add a small amount of Poisson noise to arrival rate R_t = rng.poisson(R_base) arrivals[t] = R_t processed =min(backlog[t] + R_t, C) backlog[t +1] =max(0, backlog[t] + R_t - C) ax_left.plot(np.arange(n_runs +1), backlog, color=colour, linewidth=1.8, label=label)# Inset: show a transient spike and its drainage timespike_C =100spike_backlog = np.zeros(n_runs +1)for t inrange(n_runs): R_t =95if t !=20else180# one spike at run 20 spike_backlog[t +1] =max(0, spike_backlog[t] + R_t - spike_C)ax_right.plot(np.arange(n_runs +1), spike_backlog, color="#d52a2a", linewidth=1.8)ax_right.axvline(20, color="#888888", linewidth=0.8, linestyle="--")ax_right.annotate("Spike\n(R=180, single run)", xy=(20, spike_backlog[21]), xytext=(30, spike_backlog[21] +20), fontsize=8, color="#555555", arrowprops=dict(arrowstyle="->", color="#555555", lw=0.8))for ax in (ax_left, ax_right): ax.set_xlabel("Pipeline run number") ax.set_ylabel("Backlog (records)") ax.spines["top"].set_visible(False) ax.spines["right"].set_visible(False) ax.grid(False)ax_left.set_title("Continuous throughput scenarios")ax_left.legend(fontsize=8, frameon=False)ax_right.set_title("Single spike (R=95 normally, R=180 at run 20)")fig.tight_layout(pad=1.5)plt.savefig("_assets/ch03-pipeline-backlog.png", dpi=150, bbox_inches="tight")plt.show()
Figure 4.1: Figure 3.1. Pipeline backlog under three throughput scenarios. When ingest rate exceeds processing capacity (R > C), the backlog grows without bound. When R = C, the backlog is stable — but any transient spike in arrival rate will start an accumulation that the pipeline cannot clear. The comfortable scenario (R < C) maintains a buffer that absorbs short-term spikes. Note that the matched-rate scenario, which looks safe, is the most operationally fragile: a single run at 1.1× arrival rate starts an accumulation that takes many runs to drain.
The right panel is the operationally important one. Even a pipeline running comfortably at R < C will accumulate a backlog after a single large spike if the spike is big enough. How long does the pipeline take to drain that backlog? If C = 100 and R_normal = 95, the pipeline gains five slots of capacity each run. A spike that added 80 records to the backlog will take 16 runs — 16 nightly cycles, 16 days — to drain. Downstream consumers experience 16 days of latency growth. The pipeline reported green the entire time.
The practical implication: track backlog as a metric, not just pipeline completion. Set an alert when backlog exceeds a threshold that represents acceptable latency.
4.6 Idempotency
The most important property an ETL pipeline can have is idempotency: running the same pipeline twice with the same input produces the same output, with no duplicates and no side effects.
This sounds obvious. In practice, pipelines are rarely designed this way from the start.
A pipeline that appends records on each run will, if re-run, create duplicates. A pipeline that issues DELETE followed by INSERT is not idempotent if the delete and insert are not wrapped in a transaction — a failure between the two leaves the table empty. A pipeline that sends an email notification on success will send two emails if re-run.
The canonical implementation of idempotent loading is upsert on a natural key.
-- Upsert: insert if permit_id doesn't exist, update if it does.-- Running this statement twice with the same rows produces the same-- table state as running it once.INSERTINTO permits_staging (permit_id, district_id, permit_type, issued_date, geom)VALUES (%(permit_id)s, %(district_id)s, %(permit_type)s, %(issued_date)s, ST_GeomFromGeoJSON(%(geom_json)s))ON CONFLICT (permit_id) DO UPDATESET district_id = EXCLUDED.district_id, permit_type = EXCLUDED.permit_type, issued_date = EXCLUDED.issued_date, geom = EXCLUDED.geom, updated_at = now();
The ON CONFLICT DO UPDATE clause is the key. PostgreSQL checks whether a row with the given permit_id already exists. If it does, it updates it to match the incoming row. If the pipeline is re-run with the same data, the result is identical to the first run. No duplicates.
This requires a natural key — a field or combination of fields that uniquely identifies a logical record in the source data. permit_id is a good natural key if the source system assigns stable identifiers to permits. If the source has no stable identifier, you need to construct one: a hash of the fields that define uniqueness.
What idempotency buys you operationally: when a pipeline fails partway through, you can re-run it from the beginning without cleaning up partial state. This makes recovery from failure trivial. Without idempotency, partial failure requires manual intervention to determine what was and was not loaded, and to delete the partial load before re-running.
Prefect’s task caching (shown in the extraction task above) provides idempotency at the extraction boundary: re-running the flow within the cache window does not re-call the API. The upsert provides idempotency at the load boundary. Together they ensure that re-running the entire flow is always safe.
TipWhat to try
Set ingest_rate = 105 and capacity = 100. How many runs does it take for the backlog to reach 1,000 records? What does this tell you about the importance of even small throughput deficits?
Add a “burst clearing” mechanism: after every 10 runs, double the processing capacity for one run (simulating a catch-up batch). How much does this change the long-run backlog accumulation at ingest_rate = 105?
Try ingest_rate = 100 (matched capacity) with Poisson noise (the cell uses np.random.poisson). Run it several times. Does a matched-rate pipeline stay stable, or does it drift into backlog? What does this tell you about designing capacity at exactly the expected load?
import numpy as npimport matplotlib.pyplot as plt# --- Try changing these parameters ---ingest_rate =110# Records arriving per run (average)capacity =100# Records the pipeline can process per runt_end =120# Number of pipeline runs to simulatenoise =True# Add Poisson noise to arrival rate?seed =42rng = np.random.default_rng(seed)scenarios = [ ("Low load (R=85)", 85, capacity, "#888888"), ("Matched (R=C)", capacity, capacity, "#111111"), ("Overloaded (R={})".format(ingest_rate), ingest_rate, capacity, "#d52a2a"),]fig, ax = plt.subplots(figsize=(8, 4))for label, R, C, colour in scenarios: backlog = np.zeros(t_end +1)for t inrange(t_end): R_t = rng.poisson(R) if noise else R backlog[t +1] =max(0.0, backlog[t] + R_t - C) ax.plot(np.arange(t_end +1), backlog, color=colour, linewidth=1.8, label=label)ax.set_xlabel("Pipeline run number")ax.set_ylabel("Backlog (records)")ax.set_title(f"Pipeline backlog simulation (capacity={capacity}, noise={noise})")ax.legend(fontsize=9, frameon=False)ax.spines["top"].set_visible(False)ax.spines["right"].set_visible(False)plt.tight_layout(pad=2.0)plt.show()
4.7 Exercises
3.1 — Schema validation
The pipeline described in the opening puzzle failed because district_id changed from integer to string without notice. Write a Python function validate_feature(feature: dict) -> list[str] that accepts a GeoJSON Feature and returns a list of validation errors (empty list = valid). The function should check:
Geometry is not null and is a recognised type.
district_id is present, non-null, and castable to integer.
issued_date is present and parseable as a date (ISO 8601).
permit_type is present and is one of a known set of values.
Write one test case for each check.
3.2 — Backlog arithmetic
A satellite image processing pipeline processes 50 tiles per hour. During an acquisition campaign, tiles arrive at 65 per hour for 8 hours, then return to 40 per hour.
How large is the backlog at the end of the 8-hour campaign period?
At 50 tiles/hour processing (which continues after the campaign), how long does it take to drain the backlog?
If the backlog threshold for alerting is 200 tiles (representing 4 hours of processing time), at what point during the campaign does the alert fire?
3.3 — dbt model design
You have two tables in PostGIS: raw_permits (one row per permit, schema as described in the chapter) and dim_districts (district boundaries as PostGIS geometries). Write a dbt model permits_validated that:
Casts district_id to integer, filtering out non-castable values.
Joins to dim_districts on district_id.
Adds a boolean column within_boundary using ST_Within.
Include at least three dbt schema tests in the companion schema.yml.
3.4 — Idempotency analysis
For each of the following pipeline designs, state whether it is idempotent and explain why. If it is not idempotent, describe the minimal change that would make it so:
A pipeline that runs DELETE FROM table WHERE run_date = today before inserting today’s records.
A pipeline that inserts records with INSERT INTO ... SELECT ... WHERE id NOT IN (SELECT id FROM table).
A pipeline that appends to a Parquet file by reading the existing file, concatenating new records, and writing the result back.
A Prefect flow that sends an email after every successful load.
4.8 Build this
The following is a complete, runnable implementation of the dbt + Prefect pipeline described in this chapter. It ingests a GeoJSON permit file, validates it with Prefect, loads it to PostGIS, then runs the dbt transformation model.
Prerequisites: PostgreSQL with PostGIS extension, Python 3.11+, dbt-postgres, prefect.
4.8.1 PostGIS schema
-- migrations/001_create_permits_tables.sqlCREATE EXTENSION IFNOTEXISTS postgis;CREATETABLEIFNOTEXISTS permits_staging ( permit_id text PRIMARYKEY, district_id integerNOTNULL, permit_type text NOTNULL, issued_date dateNOTNULL, geom geometry(Geometry, 4326), loaded_at timestamptz NOTNULLDEFAULT now(), updated_at timestamptz NOTNULLDEFAULT now());CREATEINDEXIFNOTEXISTS permits_staging_geom_idxON permits_staging USING GIST (geom);CREATETABLEIFNOTEXISTS permits_rejected (id bigserial PRIMARYKEY, raw_feature jsonb NOTNULL, rejection_reason text NOTNULL, rejected_at timestamptz NOTNULLDEFAULT now());CREATETABLEIFNOTEXISTS dim_districts ( district_id integerPRIMARYKEY, district_code text NOTNULLUNIQUE, district_name text NOTNULL, boundary geometry(MultiPolygon, 4326) NOTNULL);
The full permits_by_district model and its schema file are shown in the dbt section above. To run the full transformation after a load:
cd permits_dbtdbt run --select permits_by_districtdbt test --select permits_by_district
4.8.3 Prefect deployment
# flows/deploy_permits.py"""Deploy the ingest-permits flow to run nightly at 02:00 UTC."""from prefect import flowfrom prefect.deployments import Deploymentfrom prefect.server.schemas.schedules import CronSchedulefrom ingest_permits import ingest_permitsdeployment = Deployment.build_from_flow( flow=ingest_permits, name="permits-nightly", schedule=CronSchedule(cron="0 2 * * *", timezone="UTC"), parameters={"url": "https://data.example-city.gov/api/permits/v2/geojson","conn_string": "postgresql://permits_user:password@localhost/permits_db", }, tags=["permits", "nightly"],)if__name__=="__main__": deployment.apply()
# Start the Prefect server (development)prefect server start# In another terminal: deploy and start a workerpython flows/deploy_permits.pyprefect worker start --pool default-agent-pool# Trigger a manual run to testprefect deployment run 'ingest-permits-nightly/permits-nightly'
After the Prefect flow completes, the dbt run can be triggered as a final step in the flow by adding a task that calls subprocess.run(["dbt", "run", "--select", "permits_by_district"], cwd="permits_dbt"). The complete pipeline — extract, validate, load, transform, test — runs end to end with retry logic, observable state, and idempotent load behaviour.